Language Model Series
Series covering till Transformer's "Multi Headed Attention"


The revolutionary impact of language models truly took off with the introduction of the transformer architecture. In this series, we'll explore its fundamentals in simple steps.
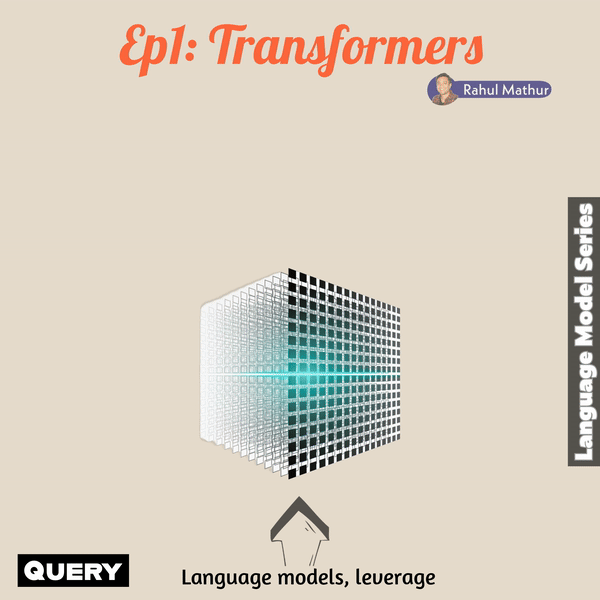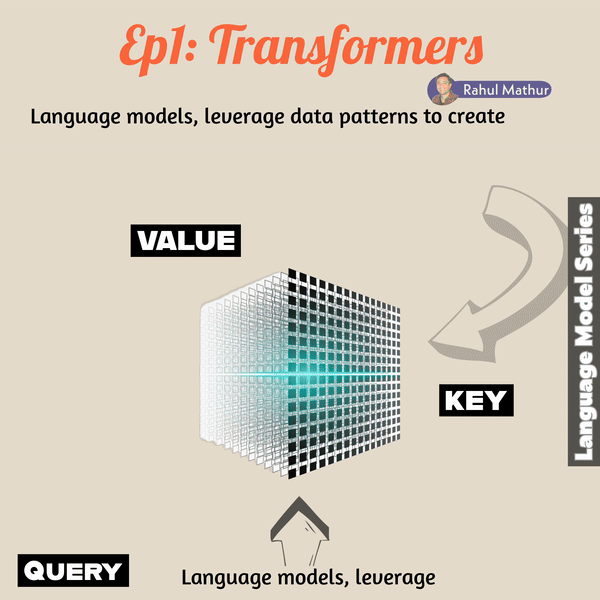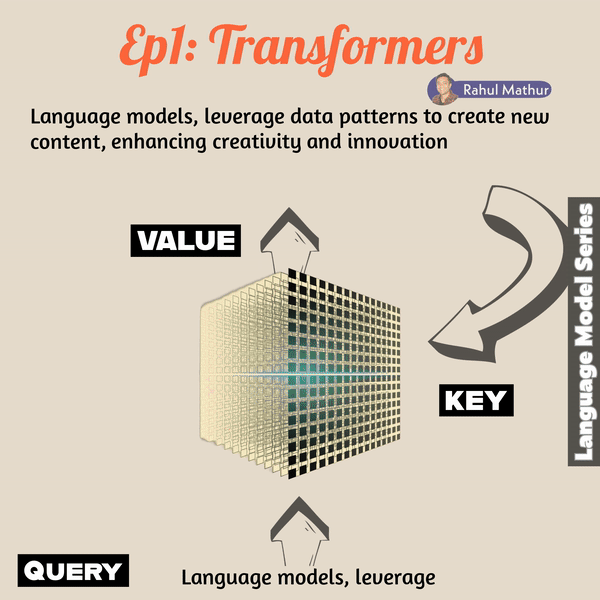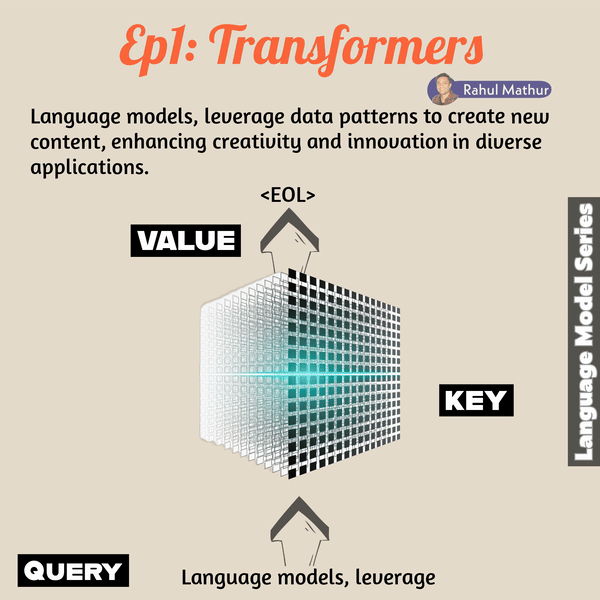
The transformer architecture addressed shortcomings seen in previous LSTM and RNN models, particularly in memory space efficiency.At a high level, transformers, envisioning them at 10,000 feet, operate akin to retriever systems. They utilize queries, keys, and values to generate outputs. What does this mean?
The pivotal paper that reshaped language models, titled 'Attention, is all you need!' analogizes the retriever to a conventional database. The user's query is analogous to an invocation, and information is fetched based on keys such as table details, schema, and indexes to derive the output value. In the transformer system, the user's natural language context serves as the query, linguistic mappings (weights and previous values) function as the key, and the output is the value.
The transformer model relies on a mechanism called "self-attention" or "scaled dot-product attention," where queries, keys, and values are used to capture relationships between different words in a sequence. This process repeats until the end of the line, effectively capturing and satisfying the contextual nuances.
The transformer architecture differs from previous LSTM models by eliminating the sequential processing bottleneck and enabling parallelization. This fundamental shift significantly enhances efficiency and performance, making transformers a ground-breaking advancement in natural language processing.

Before delving deeper, let's take a high-level look at how the Transformer is fundamentally composed, primarily consisting of Encoders and Decoders, each with its own layers. Detailed discussions on these layers will follow in later segments, but for now, let's gain an understanding:
- 𝗘𝗻𝗰𝗼𝗱𝗲𝗿𝘀: Encoders in language models are responsible for understanding the context of the input text. They process the sequential input, capturing information about the relationships and dependencies between words, the essence of their self attention mechanism.
Use Cases of Encoders: Text embedding, Image Processing, Speech recognitions… - 𝗗𝗲𝗰𝗼𝗱𝗲𝗿𝘀: On the other hand, decoders are responsible for generating output sequences based on the context provided by encoders. They attend to the encoder's output and produce sequential data step by step. Decoders are particularly crucial in tasks like language translation, where the model needs to generate a target sequence given an input sequence.
Use Cases of Decoders : Language Translation, Text Summarization, Speech Synthesis
The true power of transformers lies in their ability to seamlessly integrate encoders and decoders for tasks requiring both input understanding and output generation.
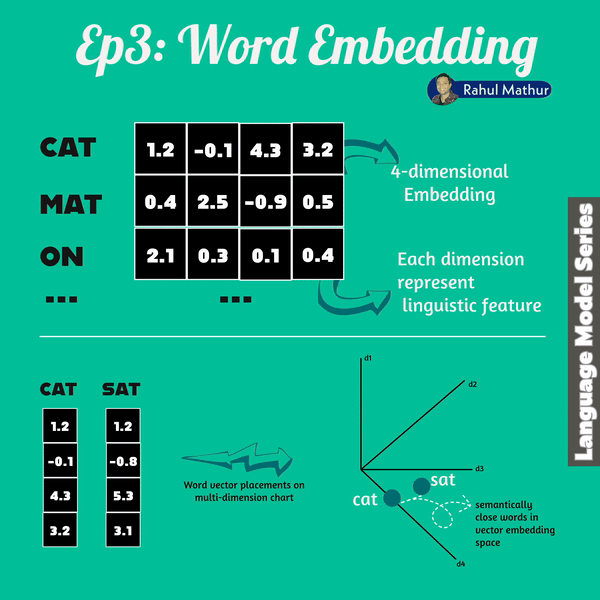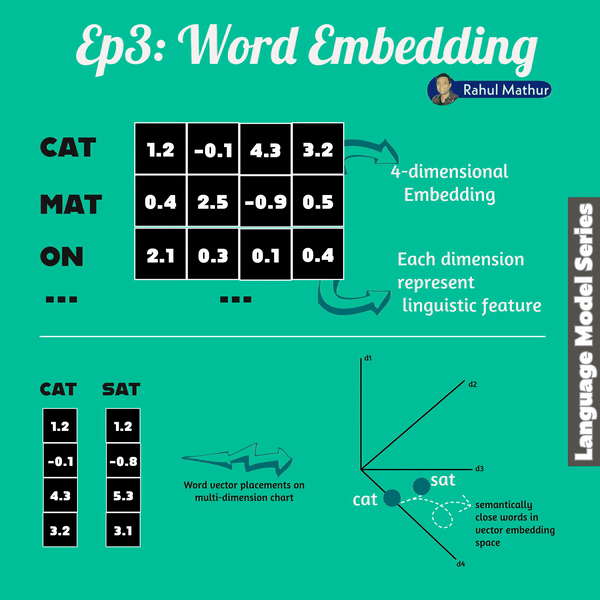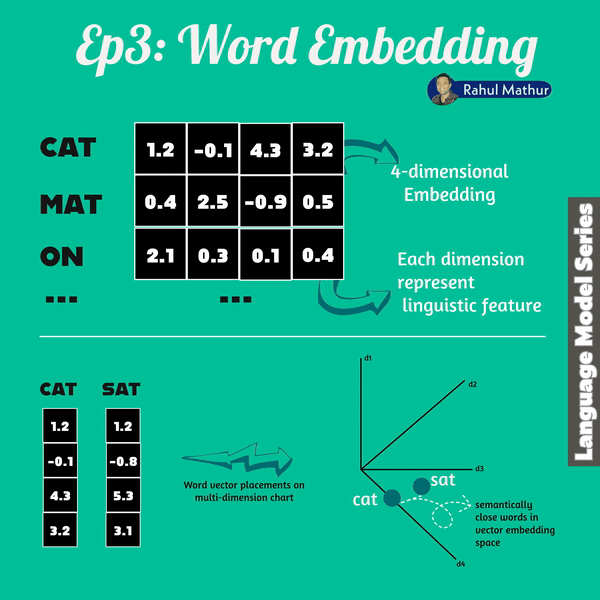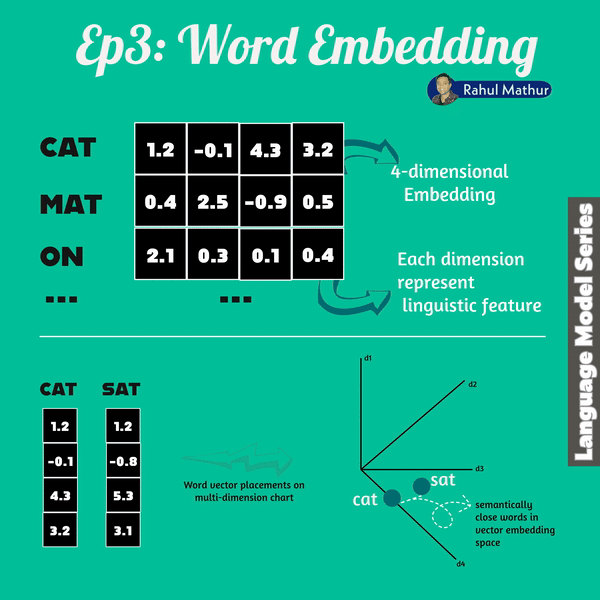
Word vectors are an essential aspect of both encoder and decoders within transformer architecture. In language models, words are translated into a sequence of numbers known as a "word vector." This breakthrough not only enhanced language understanding but also introduced the ability to perform vector arithmetic on words.
Google's word2vec project in 2013, analyzed millions of documents, and learned to position words with similar contextual usage near each other in vector space. This concept of word vectors gained substantial traction and demonstrated a remarkable property — the ability to "reason" about words through vector arithmetic.
Language models work in vector spaces with hundreds or even thousands of dimensions. Each dimension captures a different aspect of a word's meaning, allowing language models to discern subtle nuances, resulting in a more nuanced understanding of language.
Let's draw an analogy to understand further - just as geo coordinates where Haryana (in India) coordinates are close to Delhi but not Karnataka. Similarly, words with similar meanings are positioned closer together. For instance, words like "dog," "kitten," and "pet" cluster near "cat."
The multidimensional nature of word embedding allows computers to excel at reasoning within them, paving the way for sophisticated language understanding.
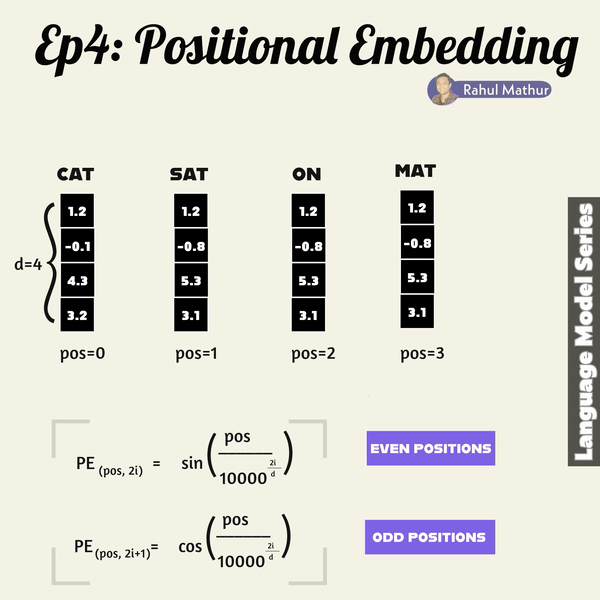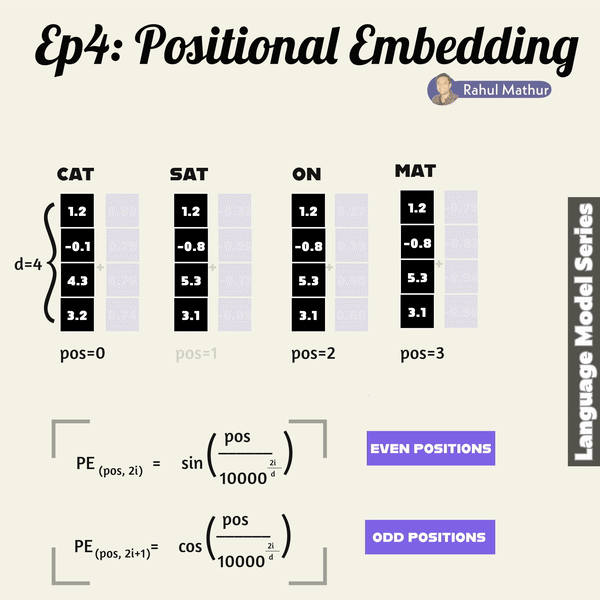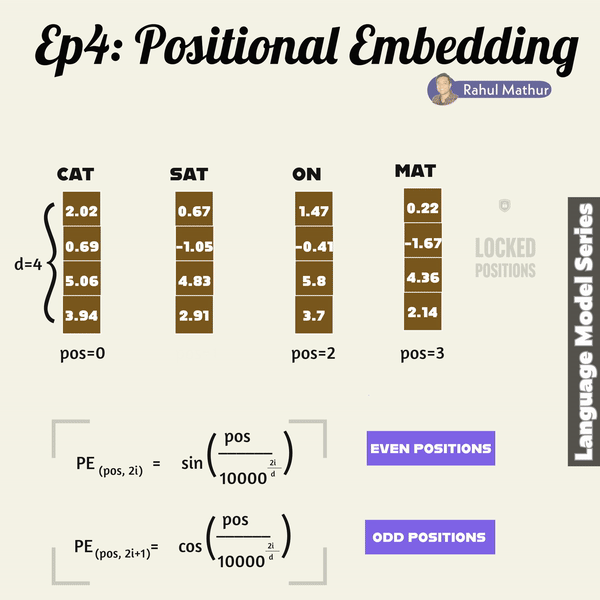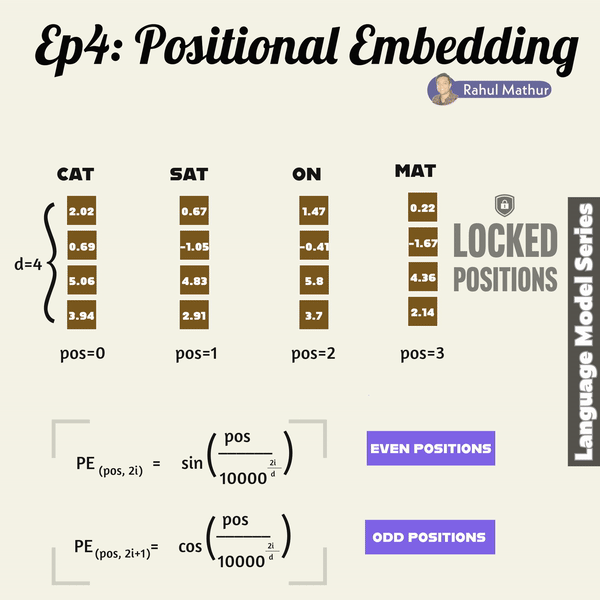
Expanding on our previous discussion of word embeddings, let's look at a crucial aspect of language models – how they grasp grammar, word placement, and context. In transformers, positional embedding plays a key role after the initial embedding process. It ensures that sentences maintain their structural positions during training, preserving the contextual order of words.
Positional embedding employs sine and cosine functions for even and odd positioned words, respectively. This strategy allows the model to create distinct positional encodings for each word in a sentence. The use of sine and cosine functions ensures a smooth and continuous representation of positions, capturing the sequential nature of language.
Consider a sentence as a sequence of words; each word is associated with a unique position. The sine and cosine functions, with varying frequencies, encode these positions. The resulting positional embeddings enrich the model's understanding of word order and context during training.
By leveraging these mathematical functions, the transformer model can effectively capture the nuanced relationships and dependencies between words, enhancing its ability to comprehend the intricate structure of language. This approach enables the model to maintain the contextual integrity of sentences, a crucial aspect in achieving sophisticated language understanding and generation.
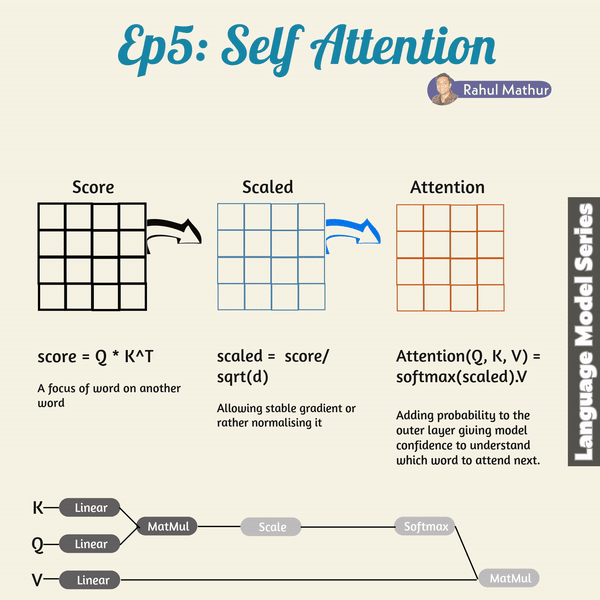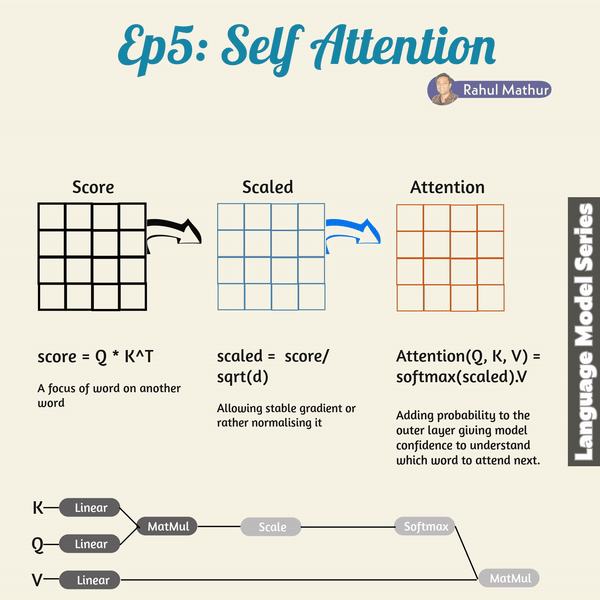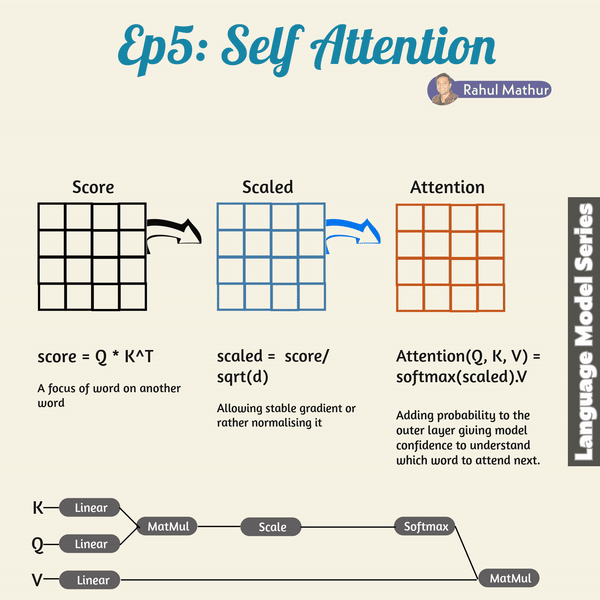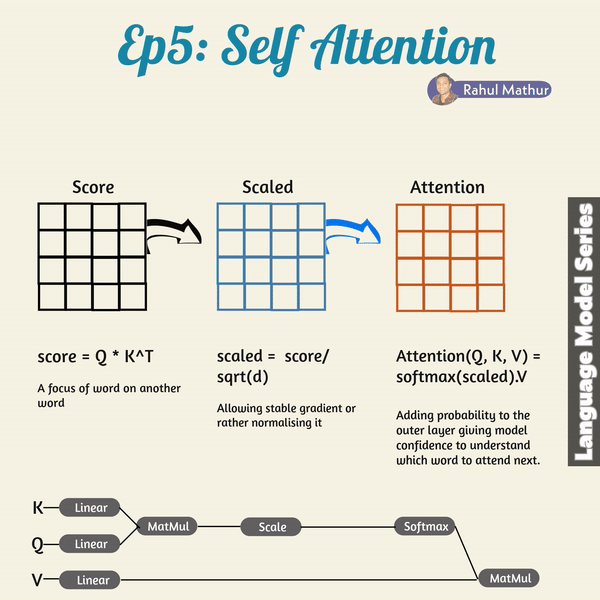
The transformer architecture introduces how the concept of self-attention can be implemented. In the self-attention mechanism, the dots products of the queries and keys are multiplied into the score matrix. The score for every word says in a way how much attention the word should pay to the other words in the input sequence. It is, thus, awarded a score that corresponds to other words, with higher scores meaning the words should pay more attention. This way, the mapping of the queries to the keys lets the model pay attention to relevant information efficiently.
However, the scores, after multiplication of the values, are scaled down through the division of the scores by the square root of the dimension of the queries and keys. This scaling keeps the potentially exploding effects of the multiplication of values in check. After the scaling of this score matrix, a softmax function is used. Through the softmax function, higher scores are emphasized with high probability value while lower scores are downscaled, so the model is confident in the attention weights it assigned to words. This way, significant words are distinguished from irrelevant words.
The attention weights resulting from this are, thus, multiplied with the corresponding value vectors to produce the output vector. The final output vector is then fed into a linear layer for further processing.
In a nutshell, self-attention is the essential component which help model understand and build the confidence of which word should come next in a sequence. Just think of possibilities on this method in NN.
<There is more to Transformers; however, the magic primarily lies till multi-headed attention>