It Gets More Creative as It Gets Hotter!
It is the Transformer based models. Almost all of these models have a feature to adjust their creativity. This article focuses on exploring these settings and their internal workings.


Introduction & Context
If you have already tried LLM models in your use cases then you must already be aware of a useful configuration - temperature. While using a model we define the temperature value to manage models generation. For example in below snippet, the temperature is defined as 0, this where model will understand that it has to be deterministic -
Model = AutoModelForCausalLM.frompretrained(
modelname,
devicemap="auto",
temperature=0,
dosample=True,
torchdtype=torch.bfloat16
)
Above code snippet is invocation of hugging face library to create an object of pre-trained causal language model.
In simple words, temperature=0, is when model is deterministic and temperature >1, when model is creative. Creative is nothing but model's randomness or permitting it to be random in predicting the word for it's generation.
Deterministic vs. Creativity
In the example where the user requests a flower, in deterministic mode (temperature = 0), the model will always generate the most probable result—in this case, a sunflower. However, as the temperature increases, more variety is introduced, leading to additional elements like leaves or even different types of flowers.
While leaves and flowers serve as a simple analogy, the core idea is that a higher temperature allows the model to explore a wider range of possible outputs, making the response more diverse and creative while still remaining contextually relevant.
How creativity works ?
We discussed that when temperature is greater than 0, the model introduces randomness, or creativity, into its outputs. Now, let's explore how temperature, along with different sampling techniques, influences text generation and shapes the final output.
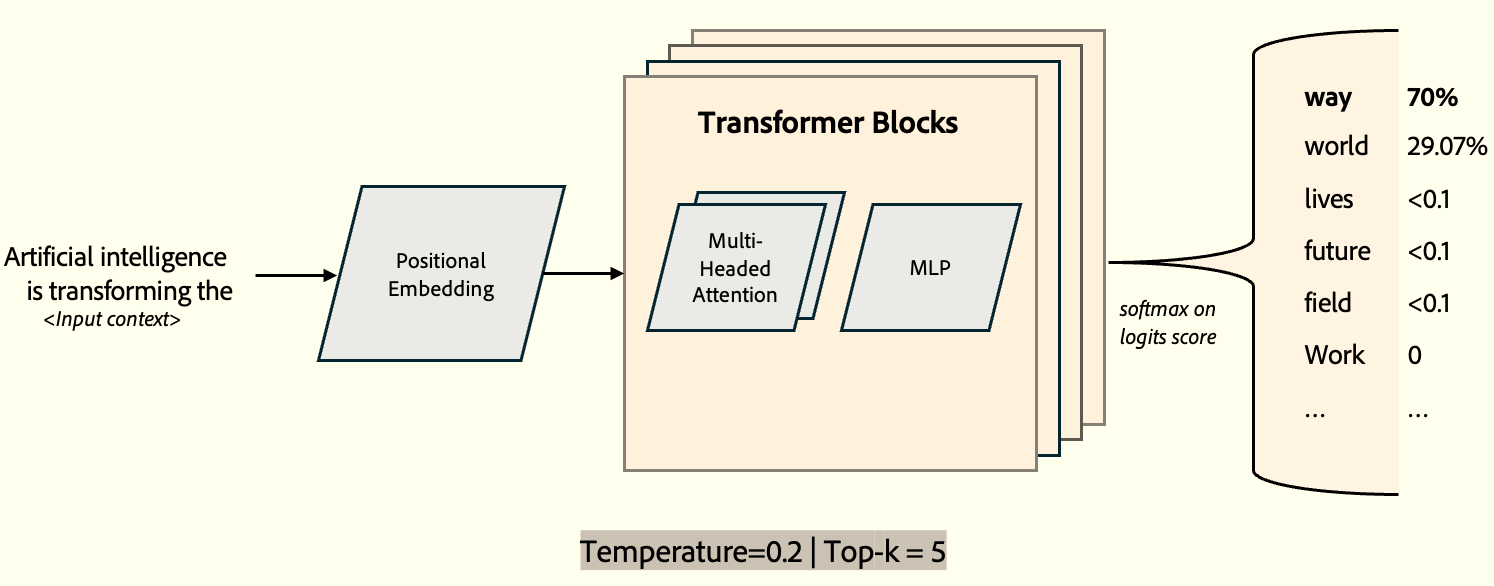
The diagram above provides a crisp representation of the Transformer architecture, focusing on the output of the Transformer block—the logit scores. As we know, logits are the raw output scores from the model (feed-forward network) before applying Softmax. The Softmax function then converts these scores into probabilities by exponentiating them and normalizing the values.
ahh! this is fine but where is temperature?

Greedy
When temperature = 0, greedy mode is activated, effectively forcing the temperature to 1 and top-K to 1.
top-K value is the top K sample values
In this case, the model becomes deterministic and always selects the token with the highest probability. Since there are no further operations and the model simply picks the top-ranked token, this approach is called greedy selection. There is no randomness and no alternative selection.
Random
When top-K sampling is combined with a temperature < 1 or > 1, the model first restricts its choices to the top-K highest-probability tokens and then applies temperature scaling before sampling.
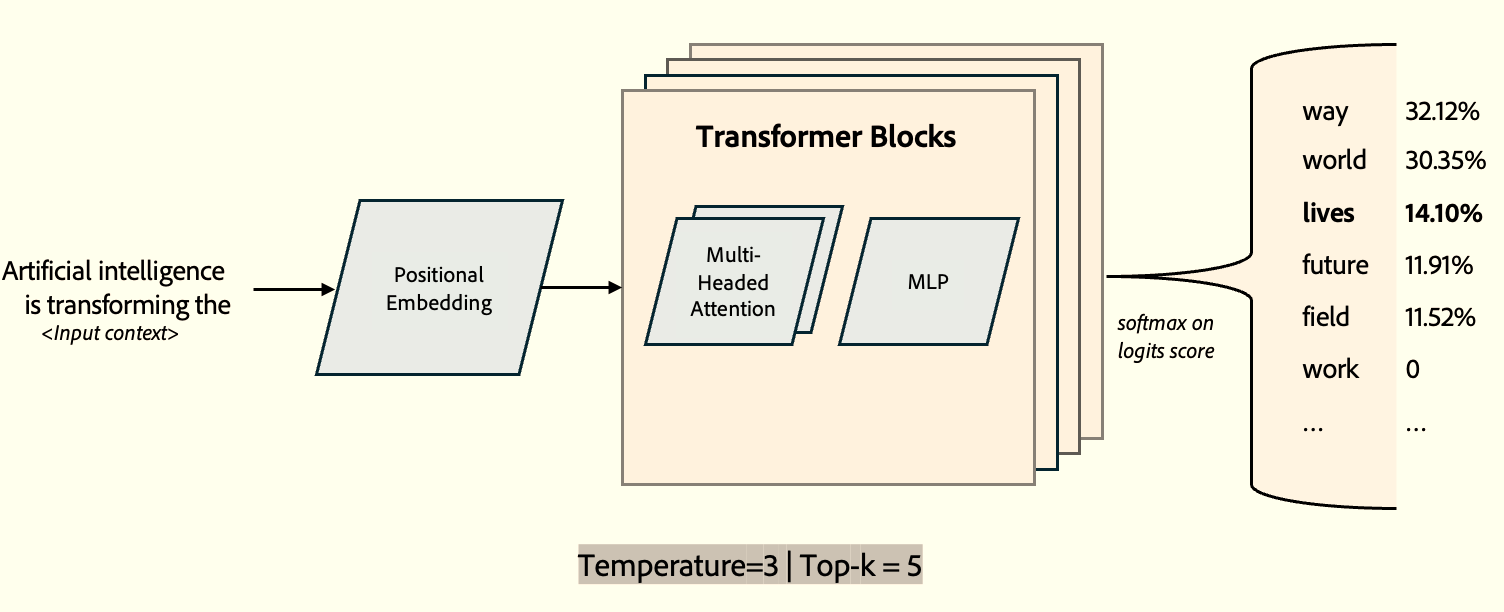
The selection process is not purely random—it follows a weighted probability distribution, favoring higher-probability tokens, especially when the temperature is low.
A nice understanding shared by Imaginary_Bench_7294 on reddit, here -
Temperature is a direct scaling value, meaning the output of the softmax function is scaled in relation to the temp. So, high temps flatten the probability distribution, whereas low temps increase the difference between the probability values. Effectively, this means that high temperatures give the AI more "high likelyhood" values to choose from, and low temperatures decrease the number of choices.
Here is an example depicting the output with higher temperature value that creates a softer probability distribution, allowing for more randomness in the generated text – what some refer to as model “creativity”.
Another parameter, top-P (nucleus sampling), is similar to top-K but operates based on a cumulative probability threshold rather than a fixed number of tokens. Instead of selecting the top-K highest-probability tokens, top-P dynamically selects the smallest set of tokens whose cumulative probability exceeds a given threshold (P). The next token is then sampled from this subset.
top-P: Considers the smallest set of tokens whose cumulative probability exceeds a threshold p, ensuring that only the most likely tokens contribute while still allowing for diversity.
Surprise
Another sampling method in LLMs is Mirostat, which adjusts the sampling process dynamically to maintain a desired level of perplexity. When Mirostat mode is set to 1 or 2, it utilizes the parameters mirostat_eta (learning rate) and mirostat_tau (target perplexity).
Speaking of Mirostat, the term perplexity becomes relevant. Perplexity measures how well a probability distribution (or model) predicts a given sequence.
- Lower perplexity indicates that the model assigns higher probability to correct words, leading to more predictable and coherent outputs.
- Higher perplexity means the model assigns higher probability to less likely words, introducing more randomness and surprise in the output.
In Mirostat sampling, temperature is still used to scale logits before computing probabilities. The mirostat_tau parameter, typically ranging from 3 to 5, helps balance coherence vs. diversity in text generation—lower values favor coherence, while higher values introduce more diversity.
Conclusion
You can choose when to leverage the creativity or determinism of the model based on your use case and configuration. Temperature serves as a powerful control in transformer architecture— a simple yet effective parameter that significantly influences the output. By adjusting it, users can tune the model’s behavior, balancing between predictable responses and creative variations.